
4. VGG16 Model
1. Introduction to VGG16
VGG16 is a deep convolutional neural network architecture that gained popularity for its simplicity and effectiveness in image classification tasks. Developed by the Visual Geometry Group (VGG) at the University of Oxford, VGG16 was introduced in the 2014 paper titled “Very Deep Convolutional Networks for Large-Scale Image Recognition” by Karen Simonyan and Andrew Zisserman. It was designed to improve upon the previous state-of-the-art in image classification, particularly in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC).
2. Components of VGG16
-
Architecture Overview
VGG16 consists of 16 layers, organized into convolutional layers followed by fully connected layers. The key components include:
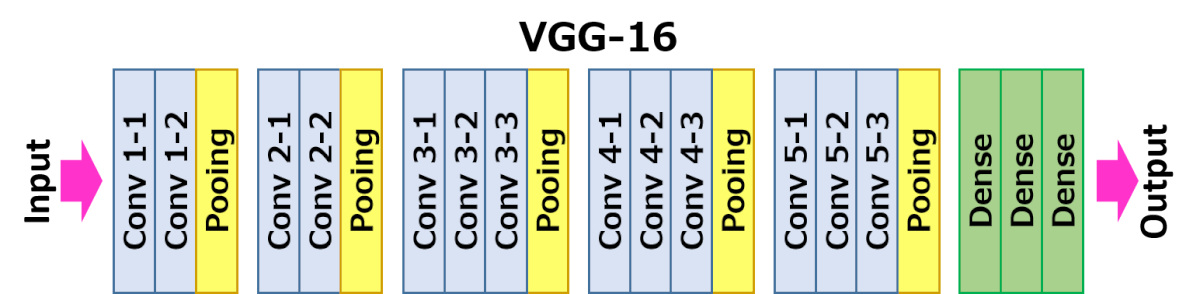
-
Input Layer: Accepts input images of fixed size (typically
pixels in RGB format). -
Convolutional Layers: The network comprises 13 convolutional layers, where each layer performs convolution with small
filters and a stride of 1 pixel. The use of small filters allows the network to learn more complex features with fewer parameters. -
Activation Function: Throughout the network, the ReLU (Rectified Linear Unit) activation function is used after each convolutional and fully connected layer:
-
Max-Pooling Layers: After some of the convolutional layers, max-pooling layers with
filters and a stride of 2 pixels are applied. Max-pooling reduces the spatial dimensions of the feature maps, making the network more robust to variations in input images. -
Fully Connected Layers: The last three layers of VGG16 are fully connected layers, which integrate high-level features for final classification. The output layer typically uses a softmax activation function to output class probabilities.
-
-
Mathematical Operations in VGG16
-
Convolution Operation: Convolutional layers apply filters to the input feature maps to extract spatial hierarchies of features:
where is the input feature map, is the filter (kernel), and are spatial coordinates. -
ReLU Activation: ReLU introduces non-linearity by replacing negative values with zero:
-
Max-Pooling: Max-pooling reduces the spatial dimensions of feature maps by selecting the maximum value from each local region:
where is the size of the pooling window (typically ). -
Fully Connected Layers: Each neuron in the fully connected layers computes a weighted sum of its inputs, followed by a bias term and activation function:
where is the weight matrix, is the input vector, and is the bias vector.
-
3. Architectural Innovations
-
Use of Small Filters: VGG16 uses
convolutional filters throughout the network, which allows for deeper architectures with fewer parameters compared to larger filters. -
Deep Architecture: With 16 layers, VGG16 demonstrated the benefit of depth in learning hierarchical features from images, improving accuracy in image classification tasks.
-
No Local Response Normalization (LRN): Unlike AlexNet, VGG16 does not use local response normalization, simplifying the architecture and training process.
4. Training and Optimization
-
Training Methodology: VGG16 was trained using stochastic gradient descent (SGD) with momentum. Data augmentation techniques such as flipping, cropping, and scaling were applied to increase the diversity of training data and improve model generalization.
-
Batch Processing: Batch processing and parallel computation on GPUs enabled faster training of deep networks like VGG16, which contained millions of parameters.
5. Impact and Legacy
-
Performance: VGG16 achieved competitive performance in the ImageNet challenge, demonstrating the effectiveness of deep convolutional neural networks for large-scale image recognition.
-
Architectural Influence: VGG16’s straightforward architecture and success inspired subsequent deep learning models, influencing advancements in computer vision tasks such as object detection, image segmentation, and facial recognition.
-
Model Variants: Variants of VGG, such as VGG19 (with 19 layers) and VGGNet, have been adapted for various applications, showcasing its versatility and robustness in different domains.